NextChat,全称为ChatGPTNextWeb,是一款开源免费的私有ChatGPT网页应用部署工具 。它适合所有人搭建Web聊天机器人,能够支持GPT3、GPT4、GeminiPro等人工智能大模型,已在Github上获得了显著的关注,这表明其在开发者和用户群体中相当受欢迎,并且该项目已被收购,这无疑预示着NextChat巨大的商业价值潜力 。
主要功能
-
一键免费部署
- 借助Vercel平台,在不到一分钟的时间里就能轻松地部署ChatGPT应用,不需要进行复杂的配置操作,也无需额外支付费用。这种高效便捷的部署方式在同类工具中具有明显的优势,无论是对于技术新手还是有经验的开发者来说,都降低了使用门槛,提高了开发效率,极大地节省了时间和成本 。
-
轻量级客户端
- NextChat提供的客户端文件大小约为5MB,并且支持Linux、Windows和MacOS等多种操作系统。小巧的文件体积方便用户快速下载和使用,多平台支持则保证了其广泛的适用性。无论是桌面端的电脑还是其他操作系统的设备,用户都可以方便地使用NextChat进行操作,不会受到系统限制而影响体验 。
-
全面的Markdown支持
- 无论是LaTex公式、Mermaid流程图还是代码高亮,都能在NextChat中得到完美支持。这一功能丰富了用户在文档编写和笔记记录时的形式,使得用户能够更加生动、多样化地呈现内容。例如,对于需要编辑含有数学公式的科技文献或者绘制工作流程图的用户来说,NextChat的Markdown支持功能可以让他们的工作更加高效、便捷,无需额外寻找专门的公式编辑工具或流程图绘制工具 。
-
隐私优先
- 所有用户的数据都是存储在本地浏览器中的。在当今数据隐私备受关注的时代,这一点尤为重要。它确保了用户的隐私安全,避免用户数据被第三方访问或利用。与其他一些将用户数据上传至云端服务器的聊天工具相比,NextChat给予用户更多关于数据安全的自主控制权,增强了用户对产品的信任 。
-
响应式设计与深色模式
- NextChat无论是在手机、平板还是电脑上,都能够提供流畅的使用体验。这得益于其响应式设计,根据不同设备的屏幕尺寸和特性进行自适应调整。而深色模式则更适合夜间阅读,不仅可以减少眼睛在低光环境下受到的蓝光刺激,还能在视觉上给用户带来一种舒适感。例如,对于那些常在夜晚使用设备,如夜间学习或者夜间工作的用户来说,深色模式在保护视力的同时,也能营造出一种专注的氛围 。
-
多语言支持
- 支持包括英语、简体中文、繁体中文等多种语言。这一功能方便不同语言背景的用户轻松切换并使用。对于全球范围内的用户来说,无论是来自中国使用简体或繁体中文的用户,还是其他国家使用英语或其他语种的用户,都可以毫无障碍地使用NextChat进行交互,扩大了NextChat的用户群体范围 。
-
简化操作流程
- 升级后的NextChat,甚至不需要接口地址,只要一个API – Key就能启用。取消了手动输入接口地址这一繁琐又专业的操作步骤,任何人都能轻松上手。无论是专业的开发者还是普通用户,都可以在几秒钟内完成设置,专注于享受AI带来的高效沟通体验,真正做到了即开即用的智能化服务,极大提升了用户的使用效率和便捷性 。
-
全面兼容领先的LLMs技术
- 作为一款全能型AI应用,NextChat全面兼容主流的大型语言模型(LLMs)。这使得它能够为用户提供流畅自然的对话体验,无论是进行内容创作、语言翻译还是问题解答,NextChat都能够借助先进的LLM技术,快速给出精准的答案,如智能对话生成能够理解上下文,还可以提供高质量的内容创作、翻译与优化服务等 。
-
企业级功能(企业版)
- 企业版提供了品牌定制、资源集成、权限管理等高级功能。品牌定制可以让企业打造具有自身特色的聊天应用,资源集成能够方便企业整合内部资源到聊天应用中,权限管理则确保企业数据的安全和隐私。这些功能有助于企业更好地进行私有化部署和定制需求,适合企业内部的使用,能够提升工作效率和数据安全性 。
-
持续更新
- 该项目持续更新,会提供多模态、智能体等前沿能力,保持技术的先进性。这意味着NextChat能够紧跟AI技术的发展趋势,不断为用户带来新的功能和更好的使用体验。例如随着多模态技术的发展,NextChat未来可能会在处理图像、语音等多种类型数据上带来更多的创新功能,满足用户更复杂多样的需求 。
安装和使用
NextChat支持众多平台,桌面端(包括Linux、Windowns、MacOS)可以直接下载安装包安装即可,对于移动端用户,建议在NAS或常开机的设备上部署Web版,并使用PWA应用(将网页模拟成客户端,体验接近客户端)。
准备工作
- 拥有 Open API key。如果没有官网的,可以使用小七的API中转站,价格更便宜(注册即送0.2美金的全模型测试服务)
- Github账号一个(白嫖服务必备,可用于登录Vercel)
- 域名(可选,可有可无,用于Vercel的话不备案的域名也可以;如果自身有服务器且是国内服务器的话,需要备案)
- 服务器或者 NAS
- docker
Vercel 一键部署
1、在 github 界面点击 Fork NextChat 项目

2、打开 vecel,点击 Add New – Project
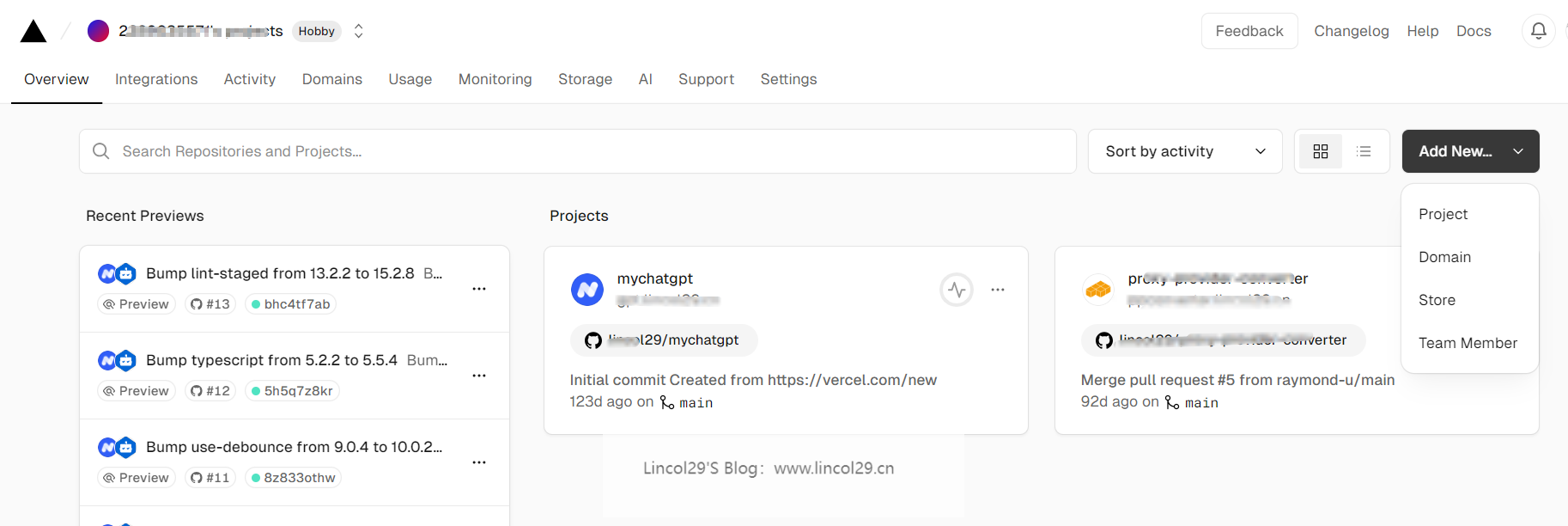
3、导入 NextChat 的 github 项目
记得在环境变量页填入 API Key 和页面访问密码 CODE;
类似这个样子,自行填写即可。
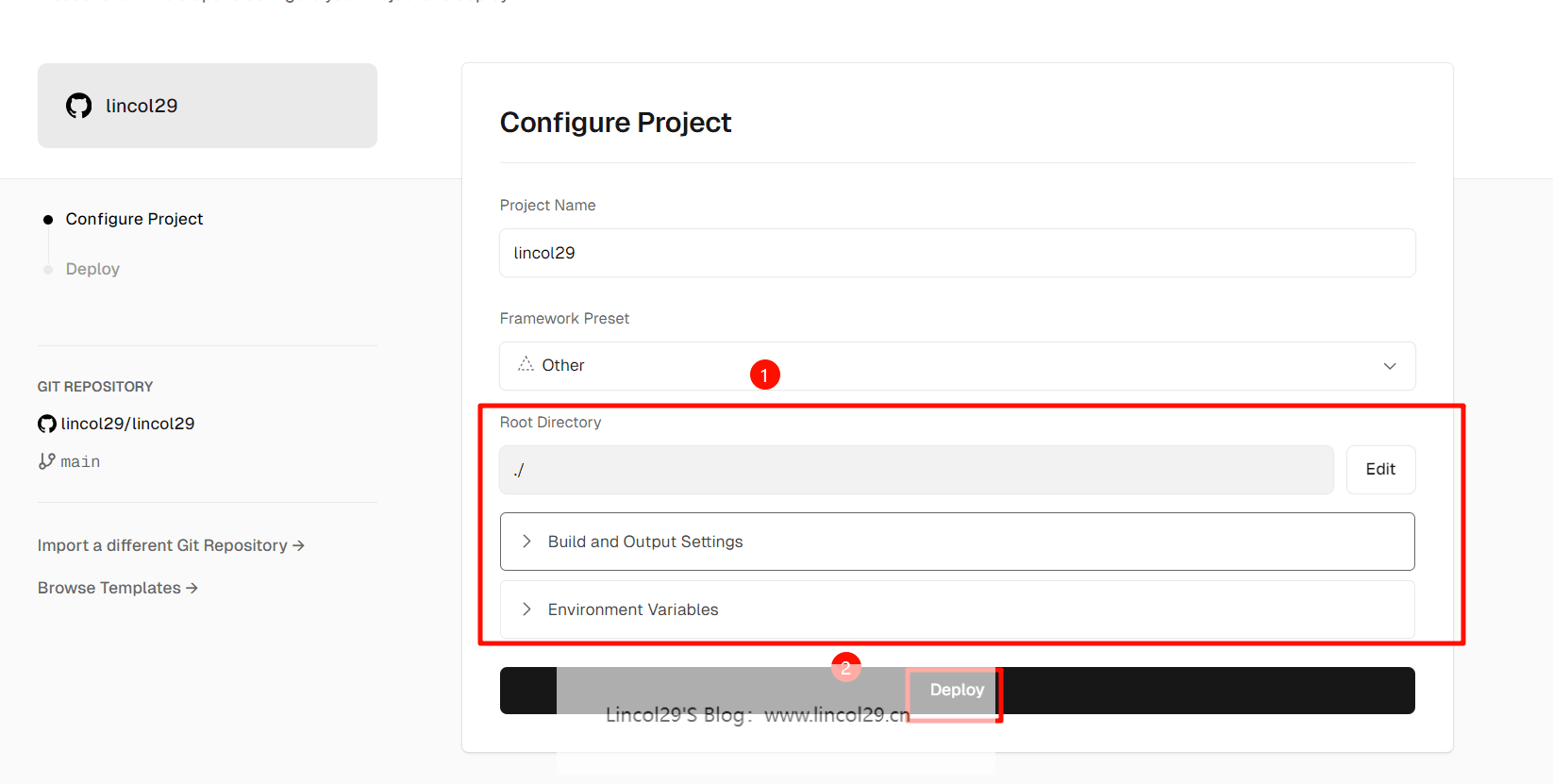
4、解析到自己的域名(可选)
目前 Vercel 分配的域名 DNS 在某些区域被污染了,绑定自定义域名即可直连。
Docker-compose 部署 NextChat
防火墙放行端口
ufw allow 3219/tcp
创建工作目录
work=/docker/nextchat && mkdir -p $work && cd $work
创建 docker-compose.yml 文件
version: '3'services: chatgpt-next-web: container_name: nextchat image: yidadaa/chatgpt-next-web:latest restart: always ports: - "3219:3000" environment: - OPENAI_API_KEY=sk-xxx #你的api key - CODE=777777 #密码 - BASE_URL=https://chat-api.xzbzq.com/ #第三方代理地址 - DEFAULT_MODEL=gpt-4o-mini #默认模型 - ENABLE_BALANCE_QUERY=1 #启用余额查询
参数说明
- 3000:3000,Web访问,端口冒号左边的端口可以其他的,看你自己喜好
- OPENAI_API_KEY,必填项,大模型的key,这个变量有两层含义,如果你直链OPENAI则就是OPENAI的KEY。如果你通过OneAPI代理则表示OneAPI上的KEY
- CODE,选填项,Web版的登录密码,支持多个,用逗号分开。建议一定要设置,而且要设置负责点,否则容易被别人刷
- BASE_URL: 选填项,模型代理地址,注意不是科学代理的意思,而是指那些代理各大模型的第三方,比如我们说的OneAPI也算,如果你使用OneAPI,就填OneAPI的地址
- PROXY_URL: 选填项,这个才是科学代理地址,例如
http://127.0.0.1:7890 user password,其中user和password是代理的用户名和密码,没有的话就不写即可 - DEFAULT_MODEL,选填项,默认的模型,还是看你是直连还是通过OneAPI,用谁就选谁的模型名称
- HIDE_USER_API_KEY,选填项,是否允许用户自己设置KEY,不允许就设置1,否则设置0
- ENABLE_BALANCE_QUERY,选填项,是否启用余额查询功能,启用就设置1,否则设置0
- DISABLE_FAST_LINK, 选填项,如果你想禁用从链接解析预制设置,将此环境变量设置为 1 即可
- CUSTOM_MODELS, 选填项,用来控制用户可选的模型列表,其格式有要求,下面详细介绍
其他更多参数(包括使用非OPENAI和OneAPI时的参数设置)可相见这个网页查看:
https://github.com/ChatGPTNextWeb/ChatGPT-Next-Web/blob/main/README_CN.md
上线服务
docker-compose up -d
使用 ip + 端口即可访问了。
如果你按照我的配置文件搭建的 nextchat,那么会提示你需要使用密码访问。输入你配置文件中的 CODE 即可
本地化应用
PC桌面端可以参考:
Release v2.15.6 XAI support · ChatGPTNextWeb/ChatGPT-Next-Web (github.com)
另外就是移动端可以使用Web版的PWA应用,可能有人不大理解,这里简单说一下。同样是在手机浏览器(使用手机自带的浏览器,比如iPhone就用Safari)打开Web网站,然后将网站发送到桌面,在桌面上就会出现一个App图标,它就是PWA应用,虽然不是原生App,但是体验要比直接在网页上使用要好得多。
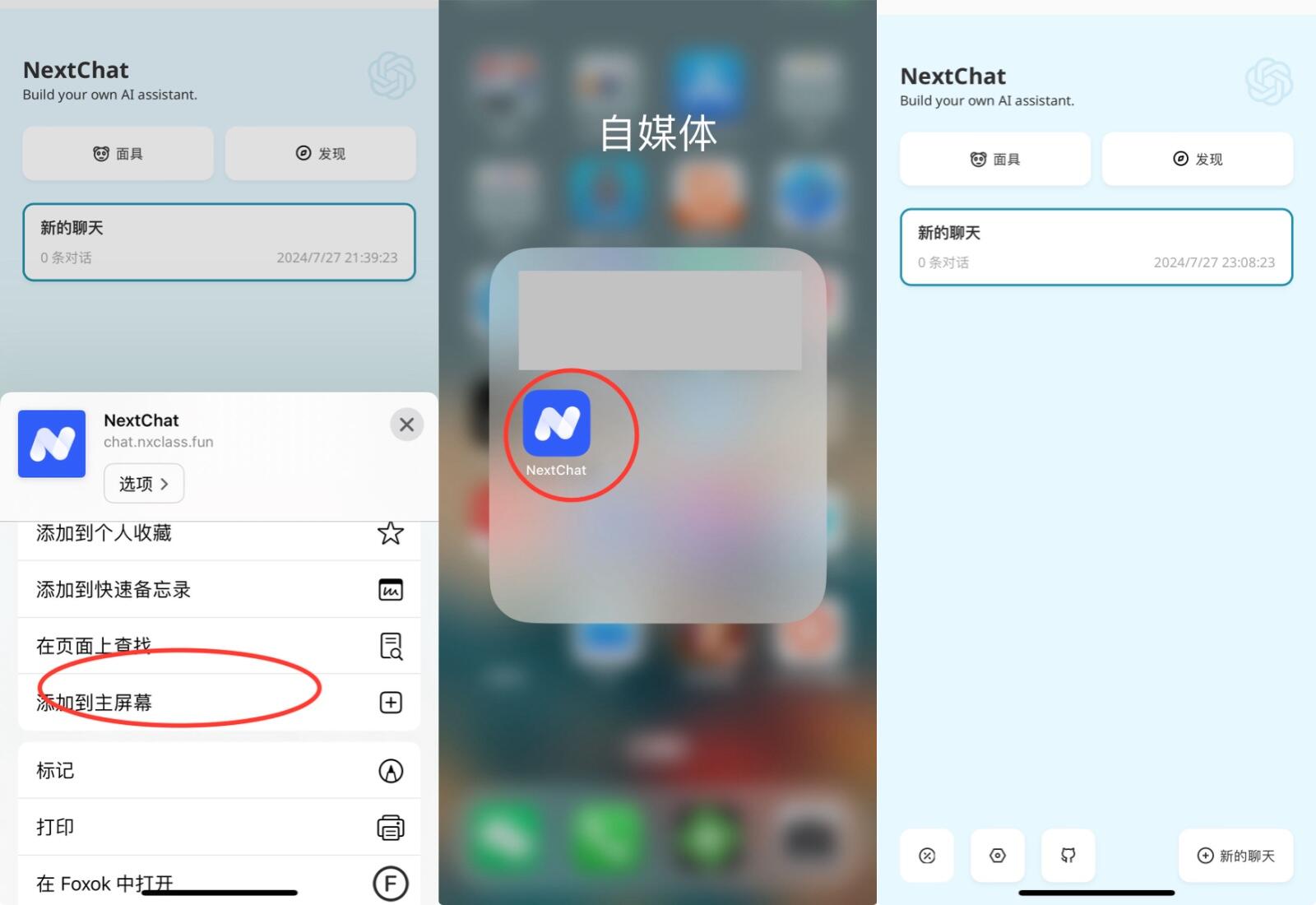
实战演习
场景1:使用面具
面具 = 多个预设提示词 + 模型设置 + 对话设置。
其中预设提示词(Contextual Prompts)一般用于 In-Context Learning,用于让 ChatGPT 生成更加符合要求的输出,也可以增加系统约束或者输入有限的额外知识。
模型设置则顾名思义,使用此面具创建的对话都会默认使用对应的模型参数。
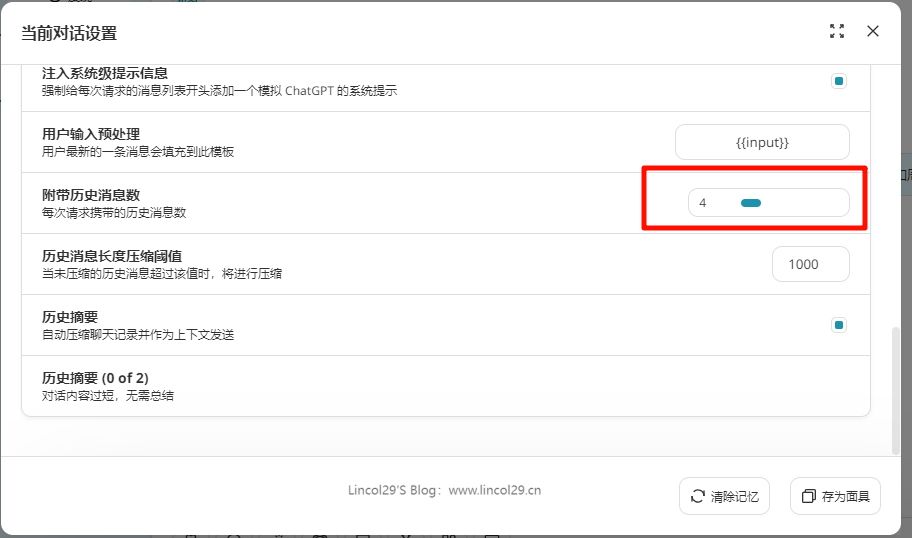
场景2:使用历史摘要
历史摘要功能,也是历史消息压缩功能,是保证长对话场景下保持历史记忆的关键,合理使用该功能可以在不丢失历史话题信息的情况下,节省所使用的 token。
由于 ChatGPT API 的长度限制,我们以 3.5 模型为例,它只能接受小于 4096 tokens 的对话消息,一旦超出这个数值,就会报错。
同时为了让 ChatGPT 理解我们对话的上下文,往往会携带多条历史消息来提供上下文信息,而当对话进行一段时间之后,很容易就会触发长度限制。
为了解决此问题,我们增加了历史记录压缩功能,假设阈值为 1000 字符,那么每次用户产生的聊天记录超过 1000 字符时,都会将没有被总结过的消息,发送给 ChatGPT,让其产生一个 100 字所有的摘要。
这样,历史信息就从 1000 字压缩到了 100 字,这是一种有损压缩,但已能满足大多数使用场景。
历史摘要可能会影响 ChatGPT 的对话质量,所以如果对话场景是翻译、信息提取等一次性对话场景,请直接关闭历史摘要功能,并将历史消息数设置为 0。
场景3:调节历史消息数